Ghost + Raspberry Pi + Cloudflare Tunnel + GitHub Actions + Vercel
Late last week, I was looking through my desk and stumbled across an older Raspberry Pi 3 B model. Not a particularly powerful unit but I thought I could possibly still make use of it.
Ghost recently released their Docker (preview) in version 6, and I've been looking for an excuse to try it. So I cooked up this idea to host a Ghost version of my site on the Raspberry Pi.
#My Requirements
- No new hardware - I could easily get a $5 VPS and run it there, but that's no fun.
- Offline tolerant - the Raspberry Pi is not intended to be production grade and could go offline at any time. The same could be said about my home internet connection.
- Maintains existing structure - my website is a weird mix of PHP running on Vercel, basically an SSR-markdown-powered static site. I'd like to keep that for now.
#Plan
Here's where I landed. There's probably better ways to do a lot of this, but this is what it looked like after spending a couple hours on it over the weekend.
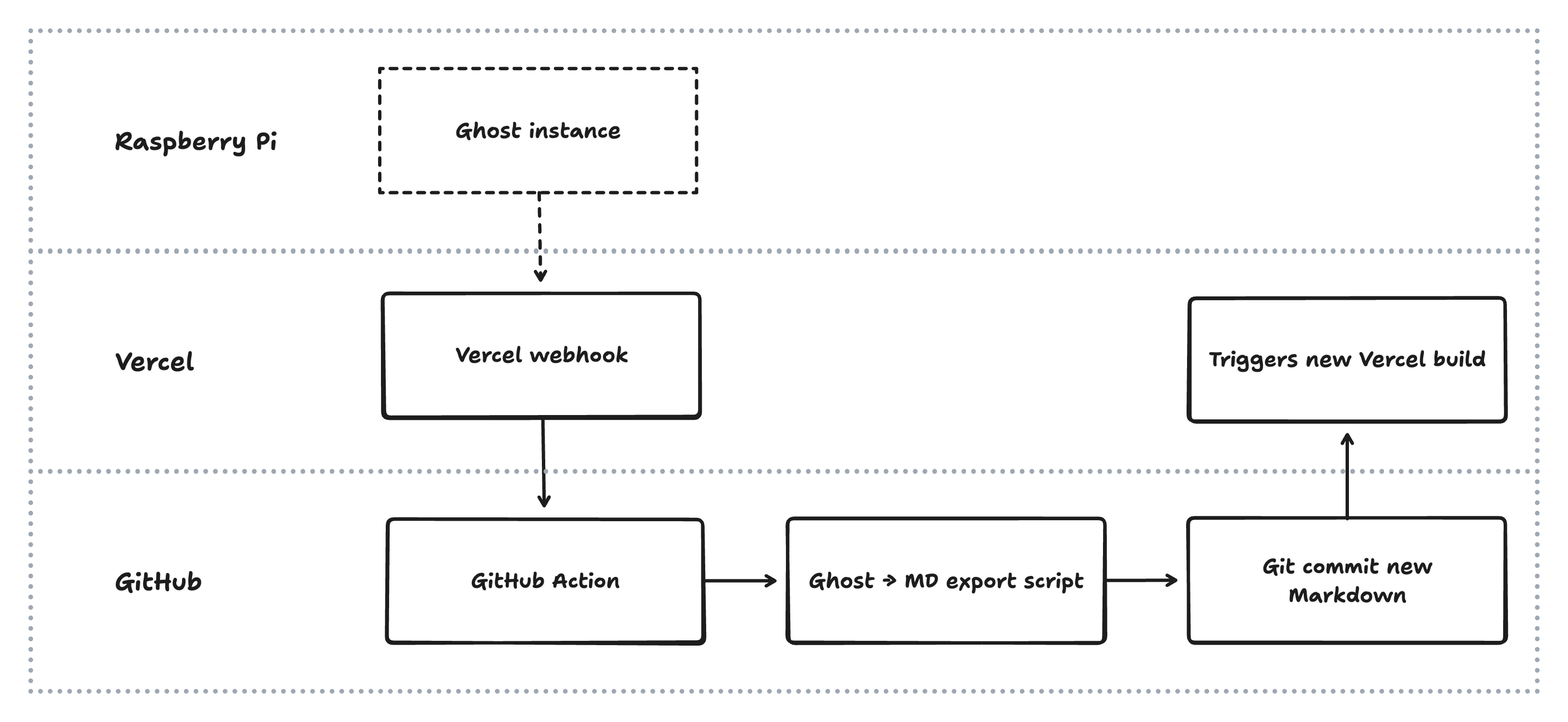
The Raspberry Pi would run the Ghost instance, which is made available to the outside world using the excellent Cloudflare Tunnel (could also use Tailscale). Even if the RPi was offline, it wouldn't matter as it's not actually serving the site – it's simply used for authoring.
The Ghost instance would have a webhook configured to target the Vercel webhook. On publish, the webhook would initiate a GitHub action, which in turn would export the content from Ghost, convert to Markdown, and it commit to the Git repository. This commit would trigger a new Vercel build, which would subsequently be deployed.
Outside of the GitHub action, there is no further requirement for the Ghost server to be online – I can disable the tunnel any time with no consequence for the running website. Plus, I can still author content using plain markdown; I just have to run the upload script to sync it back to Ghost whenever the server is back online.
#Installing Ghost
Honestly, this was the most trivial part of the step. The new Docker setup is super simple, and I had very little trouble getting it going.
// docker-compose.yml
volumes:
ghost_content:
services:
ghost:
image: ghost:5-alpine
platform: linux/arm64/v8
ports:
- "2368:2368"
environment:
NODE_ENV: development
url: ${GHOST_URL}
database__connection__filename: /var/lib/ghost/content/data/ghost.db
security__staffDeviceVerification: "false"
volumes:
- ghost_content:/var/lib/ghost/content
The one caveat is that I wanted the simplest, most portable Ghost install possible, so I'm running it in development mode. This way, my database is just a simple SQLite file. I also had to disable staffDeviceVerification as the device is unable to send email.
#Creating the Import Script
The conversion of Markdown to Ghost-friendly HTML is pretty straightforward. However, I'm using some non-standard CommonMark extensions in PHP and I wanted to make sure those things were handled both on the Markdown→Ghost import as well as the Ghost→Markdown export. This section really just discusses the setup of getting my posts into Ghost – if you're more curious about the publishing workflow, keep scrolling.
#:::image-half
I'm using a CommonMark Attributes extension to allow me to create Markdown blocks like this:
<figure class="kg-card kg-gallery-card kg-width-wide">
<div class="kg-gallery-container">
<div class="kg-gallery-row">
<div class="kg-gallery-image">
<img src="img/image1.jpg" width="1200" height="800" loading="lazy" alt="" />
</div>
<div class="kg-gallery-image">
<img src="/img/image2.jpg" width="1200" height="800" loading="lazy" alt="" />
</div>
</div>
</div>
<figcaption>First image caption | Second image caption</figcaption>
</figure>
Ghost doesn't natively support a layout like that, but they do have a gallery block. However, their galleries don't support videos and photos mixed, so we have to handle those a bit differently. Here's what I landed on to parse those Markdown blocks to galleries:
function imageHalf(md: string) {
// :::image-half \n  \n ^^^ caption \n  \n ^^^ caption \n :::
return md.replace(
/:::image-half\s*\n([\s\S]*?)\n:::/g,
(_m, content) => {
// Check if content contains video elements or video file references
const hasVideo = content.includes('<video') || /!\[[^\]]*\]\([^)]*\.(mp4|webm|mov)\)/i.test(content);
if (hasVideo) {
// Preserve as markdown block if videos are detected
return `\`\`\`markdown\n:::image-half\n${content}\n:::\n\`\`\``;
}
const images: { src: string; alt: string; caption?: string }[] = [];
// Split content into lines and process
const lines = content.split('\n').map(line => line.trim()).filter(Boolean);
for (let i = 0; i < lines.length; i++) {
const line = lines[i];
// Check if this line is an image
const imgMatch = line.match(/!\[([^\]]*)\]\(([^)]+)\)/);
if (imgMatch) {
const [, alt, src] = imgMatch;
// Check if the next line is a caption (starts with ^^^)
const nextLine = lines[i + 1];
let caption: string | undefined;
if (nextLine && nextLine.startsWith('^^^')) {
caption = convertMarkdownCaptions(nextLine.replace(/^\^\^\^\s*/, ''));
i++; // Skip the caption line since we've processed it
}
images.push({ src, alt, caption });
}
// Skip standalone ^^^ lines that aren't image captions
}
if (images.length === 0) return _m; // Return original if no images found
// Create Ghost gallery card HTML structure
const galleryImages = images.map(img =>
`<div class="kg-gallery-image">
<img src="${img.src}" width="1200" height="800" loading="lazy" alt="${img.alt}" />
</div>`
).join('\n ');
// Combine all captions for overall gallery caption
const galleryCaption = images.map(img => img.caption).filter(Boolean).join(' | ');
return `<figure class="kg-card kg-gallery-card kg-width-wide">
<div class="kg-gallery-container">
<div class="kg-gallery-row">
${galleryImages}
</div>
</div>${galleryCaption ? `\n <figcaption>${galleryCaption}</figcaption>` : ''}
</figure>`;
}
);
}
For blocks that have videos and photos mixed, we actually just preserve the Markdown as a Ghost markdown block, so that our export script can simply export it as-is. Feels like a bit of a workaround, because it is!
#Images & Captions
These were pretty easy! We'll need to make sure we also preserve image caption Markdown. Here's a Regex that targets captions but excludes Ghost Markdown blocks.
function mdCaptionToFigure(md: string) {
// Convert \n^^^ caption to <figure><img /><figcaption>... or <figure><video /><figcaption>...
// But skip content inside markdown code blocks
return md.replace(
/```markdown\n([\s\S]*?)\n```|!\[([^\]]*)\]\(([^)\s]+)\)\s*\n\^\^\^\s*([^\n]+)/g,
(match, codeContent, alt, src, cap) => {
// If this is a markdown code block, return it unchanged
if (codeContent !== undefined) {
return match;
}
// Otherwise process the image/video caption
const isVideo = /\.(mp4|webm|mov)$/i.test(src);
if (isVideo) {
return `<figure><video src="${src}" controls></video><figcaption>${convertMarkdownCaptions(cap)}</figcaption></figure>`;
} else {
return `<figure><img alt="${alt}" src="${src}" /><figcaption>${convertMarkdownCaptions(cap)}</figcaption></figure>`;
}
}
);
}
#Processing Pipeline
There's a few steps to transforming the Markdown to Ghost-ready content. Some is handled with my own custom parsing functions, the majority is then converted using micromark, and finally converted to Lexical format using Ghost's own @tryghost/kg-html-to-lexical package. The sequence roughly follows this progression:
- Read the Markdown files (I pass a directory as an argument to the script)
- Parse the front matter and title, slugify it (I should probably use the Ghost slug function instead of my own, but I don't have any collision issues yet)
- Start converting the content to HTML
- Handle
:::image-half - Handle image captions
- Convert to HTML using micromark
- Absolute-ize the images (since they live in the GitHub repo and not on Ghost)
- Convert to Lexical format
- Upload to Ghost using the Ghost Admin API JavaScript client
That's it! All of my existing content is now in Ghost.
#Export Script
Now that the content is all in Ghost, we can get to work with the publishing flow. Since we've already built the import functionality, we simply need to work in reverse to create the export functionality.
Unfortunately, it's not quite that simple, but here's a couple of solutions I ended up with.
#Lexical Content
Some types of content felt a bit easier to parse directly from the Lexical format, such as code blocks and images.
function processLexicalContent(lexicalStr?: string): { videos: Array<{src: string, caption: string, alt: string}>, markdownBlocks: string[] } {
const videos: Array<{src: string, caption: string, alt: string}> = [];
const markdownBlocks: string[] = [];
if (!lexicalStr) return { videos, markdownBlocks };
try {
const lexical = JSON.parse(lexicalStr);
function processNode(node: any) {
// Handle video blocks
if (node.type === 'video') {
videos.push({
src: node.src || '',
caption: node.caption || '',
alt: node.alt || node.fileName || ''
});
}
// Handle code blocks that might contain preserved markdown (both 'code' and 'codeblock' types)
// We're using this to support :::image-half blocks that contain videos (workaround since Ghost doesn't support videos in galleries)
if ((node.type === 'code' || node.type === 'codeblock') && node.language === 'markdown') {
markdownBlocks.push(node.code || '');
}
// Recursively process children
if (node.children && Array.isArray(node.children)) {
node.children.forEach(processNode);
}
}
if (lexical?.root?.children) {
lexical.root.children.forEach(processNode);
}
} catch (e) {
console.error('Error processing lexical content:', e);
}
return { videos, markdownBlocks };
}
We'll re-use the result of this function later.
#Galleries
While the Ghost gallery block was an excellent solution for my :::image-half blocks, unfortunately Ghost does not support captions on a per-image basis for these. Thankfully, we just saved our caption with a pipe | separator in our import script, so we can now easily just split it on that.
Since we're going to re-process the HTML later, we'll add placeholders for all of the converted content so it's easier to find our place again. For example, for our :::image-half component:
function preprocessGhostGallery(html: string): { html: string, placeholders: Record<string, string> } {
const doc = parse(html);
const nhm = new NodeHtmlMarkdown();
const placeholders: Record<string, string> = {};
const galleryCards = doc.querySelectorAll('figure.kg-gallery-card');
galleryCards.forEach((figure, index) => {
const images = figure.querySelectorAll('img');
if (images.length === 0) return;
// Extract and convert gallery caption to markdown if it exists
const figcaption = figure.querySelector('figcaption');
let galleryCaption = '';
if (figcaption) {
// Convert caption HTML to markdown to preserve formatting
galleryCaption = nhm.translate(figcaption.innerHTML).trim();
}
// Split caption by | for individual images
const splitCaptions = galleryCaption ? galleryCaption.split('|').map(c => c.trim()) : [];
let result = ':::image-half\n';
images.forEach((img, imgIndex) => {
// Start each image block with ^^^
result += '^^^\n';
const src = img.getAttribute('src') || '';
const alt = img.getAttribute('alt') || '';
result += `\n`;
// Add caption if exists (this also serves as the closing ^^^)
const caption = splitCaptions[imgIndex] || '';
if (caption) {
result += `^^^ ${caption}\n`;
} else {
// No caption, but we still need the closing ^^^
result += '^^^\n';
}
});
result += ':::';
// Create a unique placeholder
const placeholder = `GHOSTGALLERY${index}`;
placeholders[placeholder] = result;
// Replace the figure with a paragraph containing the placeholder to preserve spacing
const placeholderNode = parse(`<p>${placeholder}</p>`);
figure.replaceWith(placeholderNode);
});
}
#Putting it all together
I won't go into all of the details – if you want to check out the source code, you can see the Ghost export script here.
The sequence is basically this:
- Fetch all posts from Ghost
- Process Lexical content (videos, markdown blocks that contain videos)
- Download and rewrite images (these need to be in the repo as that's how they get added to the public site)
- Pre-process HTML (images, captions, markdown code blocks)
- Convert to Markdown using
node-html-markdown - Replace placeholders and our Markdown video blocks
- Final post-processing of Markdown (some node-html-markdown escaping quirks that didn't match the format
- Save or update
.mdfiles in the GitHub repo
#Publishing Flow
Now that we've got all of the pieces, let's put them together!
First, we'll create the GitHub Action:
// .github/workflows/sync-blog.yml
name: Sync blog (Ghost → MD)
on:
workflow_dispatch:
inputs:
event_type:
description: 'Event Type'
required: true
default: 'ghost-publish'
type: string
jobs:
export:
runs-on: ubuntu-latest
permissions:
contents: write
steps:
- uses: actions/checkout@v4
- uses: oven-sh/setup-bun@v2
- run: bun install
- name: Export posts → content/blog
run: bun tools/ghost-export-md.ts
env:
GHOST_URL: ${{ secrets.GHOST_URL }}
GHOST_CONTENT_KEY: ${{ secrets.GHOST_CONTENT_KEY }}
GHOST_ADMIN_KEY: ${{ secrets.GHOST_ADMIN_KEY }}
- name: Commit changes (if any)
run: |
git config user.name "ghost-bot"
git config user.email "ghost-bot@users.noreply.github.com"
git add content/blog public/img
git diff --cached --quiet || git commit -m "chore: export blog"
git push
This action will setup Bun and directly execute the export script, which will cause any changed or new posts to be added to VCS. The commit and push will automatically trigger a Vercel deployment.
Now, we need a webhook. I'll create a new file in the /api directory of my repository, which Vercel will automatically turn into a serverless function:
// /api/ghost-hook.mjs
export default async function handler(req, res) {
if (req.method !== "POST") return res.status(405).json({ error: "Method not allowed" });
try {
const repo = process.env.GH_REPO;
const token = process.env.GH_TOKEN;
if (!repo || !token) {
return res.status(500).json({ error: "Missing GH_REPO or GH_TOKEN environment variables" });
}
const response = await fetch(`https://api.github.com/repos/${repo}/actions/workflows/sync-blog.yml/dispatches`, {
method: 'POST',
headers: {
'Authorization': `Bearer ${token}`,
'Accept': 'application/vnd.github.v3+json',
'Content-Type': 'application/json',
'User-Agent': 'vercel-webhook'
},
body: JSON.stringify({
ref: 'main',
inputs: {
event_type: 'ghost-publish'
}
})
});
if (response.status === 204) {
console.log('Workflow triggered successfully');
return res.status(200).json({ success: true, message: "Workflow triggered" });
} else {
const errText = await response.text();
console.error('GitHub API error:', response.status, errText);
throw new Error(`GitHub API returned ${response.status}: ${errText}`);
}
} catch (error) {
console.error('Error triggering workflow:', error);
return res.status(500).json({ error: error.message });
}
}
Let's hook this up to Ghost. In the Ghost admin, we can create a new "custom integration". This is also where we'll get the Content API Key and the Admin API Key that are needed by our import and export scripts.
I created a webhook for the Post published and Post updated events, but I could add more if needed.
#That's it!
Now, I hit publish on Ghost, which fires that webhook (the Vercel serverless function). In turn, that function triggers the GitHub Action that will export the Ghost content, add it to VCS, and create a new commit. Finally, that commit automatically triggers the new Vercel build.
You can check out the full code on GitHub.